LiTA (Linfer Text Analytics) 機能紹介
LiTA の機能(分析ツール)を紹介します。以下の機能は、LiTA の「プロジェクト画面(分析ページ)」にて利用いただけます。
アップロードされたテキスト(群)はプロジェクトとして登録され、プロジェクト画面で操作いただけます。
-
諸元表・本文
プロジェクトに含まれる本文テキスト、文数などのテキスト情報を表示する。 -
単語列頻度 (TF/IDF)
プロジェクト内での特定の単語列の 出現頻度 を調べる。 -
トピックモデル
プロジェクト内の単語のトピック分析を LDA で実施する。 -
共起ネットワーク
出現パターンが近い単語同士を線で繋ぎ、ネットワーク図を表示する。 -
KWIC
プロジェクト内での特定の単語列の 出現箇所 を調べる。 -
時系列ヒストグラム
プロジェクト内での特定の単語列の 出現頻度の時系列変化 を調べる。 -
対応分析
単語頻度から算出された 単語列とメタデータのクロス集計結果 を散布図として表示する。
その他
諸元表
プロジェクトに含まれるドキュメントのタイトル(CSV の場合、id または title)と文数、単語数および文字数が表示されます。
最大 50 件の表示が可能です。
本文
ペインヘッダー(機能の表示画面上部)からドキュメントタイトル(または ID)を選択すると、本文(CSV の場合、body に指定したカラム)が表示されます。
最大 50 件の表示が可能です。
単語列頻度 (TF/IDF)
概要
テキスト中に出現する単語や単語列(単語 N-gram)を表示します。
以下のパラメータがあり、ペインヘッダーから設定可能です。
| パラメータ | 初期値 | 説明 |
|---|---|---|
| N | 3 | “単語 N-gram” の N を、1 以上 5 以下で指定します。 初期値の単語列の例)京都 大学 前 |
| 表示数 | 20 | 単語列頻度を上位何件表示させるか、1 以上 1000 以下で指定します。 |
| ソート関数 | TF による | 単語 N-gram のソート方法を指定します。 単語の出現回数(TF)による比較か、TF-IDF による比較かを選択できます。 |
| 品詞フィルター | 内容語のみ表示 | 特定の品詞のみを表示、もしくは除外します。 |
品詞についての詳細はこちらを参照してください。
用語について
- 単語 N-gram:連続した N 個の単語列
- TF (Term Frequency):プロジェクトの全テキスト内における該当の単語列の出現回数
- DF (Document Frequency):該当の単語列が 1 箇所以上含まれるドキュメントの数
- IDF (Inverse Document Frequency):該当の単語列がドキュメント内に出現する稀少度(低頻度率)を示す数値
- TF-IDF:TF と IDF の値を掛け合わせて計算。値が大きい = 頻出するが稀少性も高い単語列
定義
全ドキュメントの個数を \( D \) とするとき、単語 N-gram \( g \) の IDF は次式で与えられます:
\[ \text{IDF} (g) = \log \frac{D}{\text{DF} (g)}. \]
ここで対数 \( \log \) は自然対数を表します。
さらに \( G \) を全 N-gram の出現回数、つまりすべての N-gram にわたる和 \( G = \sum \text{TF} (g) \) として、N-gram \( g \) の TF-IDF を
\[ \text{TF-IDF} (g) = \frac{\text{TF} (g) \cdot \text{IDF} (g)}{G} \]
で定義します。ただし便宜上、\( D = 0 \) のときは \( \text{TF-IDF} (g) = - \infty \) と定め、\( D \neq 0 \) でかつ \( \text{TF} (g) = \text{DF} (g) = 0 \) のときは \( \text{TF-IDF} (g) = 0 \) と定めます。
トピックモデル (LDA; Latent Dirichlet Allocation)
概要
トピックモデルの一つである (LDA; Latent Dirichlet Allocation) を計算して結果を表示します。 ドキュメントは複数のトピック(共通性のあるテーマ)から構成されると仮定し、それぞれのトピックが生成する(トピックに分類される)単語の確率分布を推定する手法で、 ドキュメントの特徴や類似性を判別できます。
ペインヘッダー内の機能
トピック
トピック数が項目となっているドロップダウンがペインヘッダーにあります。 この項目を選択することで、そのトピック数での LDA の結果が表示されます。
eval.
以下の値を、各トピック数での LDA の計算毎に表示します。
- LDA による perplexity
- トピックが生成する単語の一貫性 (topic coherence)
ダウンロード
ダウンロードアイコンから、計算結果や eval. のデータは CSV 形式でダウンロードできます。
パラメータ設定の確認と再計算
設定アイコンから LDA のパラメータ設定の確認と再計算を行うことができます。
パラメータ設定では以下の項目があります。
- 品詞
- トピック数
- 生成する単語の出現条件
「再計算を開始する」ボタンを押すと、設定されたパラメータで LDA を再計算します。
計算結果の表示
計算結果は以下の通りに表示されます。 各項目は「on/off」ボタンで表示・非表示を切り替えることができます。
時系列グラフ
ドキュメントに日付が紐付いている (メタデータ“date“が存在する) 場合、ドキュメントに対する各トピックの確率を日付ごとに足し合わせた値をグラフで表示します。 グラフの縦軸は確率を足し合わせた数値、横軸は日付です。
日付の設定については時間・日付についてを参照してください。
トピック/単語
トピックが生成する単語と生成確率を、生成確率の大きい単語からトピック毎に表示します。
最初は5つが表示されています。数字を入力して「update」ボタンを押すことで表示される単語数を変えることができます。
トピック/ドキュメント
ドキュメント毎のトピックの分布を表示します。
ドキュメントに日付が紐付いている場合、表示するドキュメントを日付で絞り込むことができます。
共起ネットワーク
概要
文章内の出現パターンが似た(共起する)単語同士を線で結んだ「ネットワーク図」を描画します。以下のパラメータがあります。
| パラメータ | 初期値 | 説明 |
|---|---|---|
| エッジ数 | 20 | 描画する共起関係(エッジ)の件数を指定します。初期設定では、上位 20 件を表示します。 |
| Jaccard 係数 | 0.2 以上 / 0.8 以下 | 共起の強度が高い単語を「~以下」を指定して除外、もしくは低い単語を「~以上」を指定して除外します。常に共起するような単語対がノイズとなることを防ぎます。 |
| 品詞フィルター | 内容語のみ表示 | 特定の品詞のみを表示、もしくは除外します。 |
| サブグラフ検出(community detection) | オン | 関連度の高い単語同士を同色(最大 30 色)で描画します。エッジ数を 31 以上に指定した場合は、1 色で描画します。 |
| 出現頻度によって円の大きさを変える | オン | 出現頻度が高ければ、単語円(ノード)を大きく描画します。他の単語との相対頻度によって、円のサイズが決定されます。 |
品詞についての詳細はこちらを参照してください。
詳細
共起関係(エッジ)の表示
Jaccard 係数の高い(共起が高強度である)単語対ほど、太いエッジで結ばれます。エッジの長さやノード間の距離に意味づけはありません。
Jaccard 係数
文単位で共起の頻度を数え、以下の計算式によって、共起の強度をJaccard 係数として算出します。 共起している割合が高ければ高いほど、その単語間の Jaccard 係数は大きく(1 に近い値に)なります。
具体的には、二つの単語 \( g_1, g_2 \) に対して、それぞれが含まれる文全体の集合を \( A_1, A_2 \) とするとき、単語間の Jaccard 係数は
\[ \text{Jac} (g_1, g_2) = \frac{| A_1 \cap A_2 |}{| A_1 \cup A_2 |} \]
で計算されます。つまり二つの単語の 両方 を含む文の数を、二つの単語の 少なくともどちらか一方 を含む文の数で割った値となります。
サブグラフ検出(community detection)
一般的なネットワークグラフには、グラフ内をグルーピングする community と呼ばれる構造があり、 community 内部のエッジの重みが大きくなるように、グラフを複数の communities へ分割する問題が知られています。 この問題は community detection、あるいは KH Coder では サブグラフ検出 と呼ばれています。
LiTA においては、Vincent D. Blondel らによる Louvain 法に基づいて、近似的に community detection を行います。 なお、効率化およびアルゴリズムの有限性の保証のため、次の変更を施しています:
- 「Modularity を極大化し、singlet community からなる新たなグラフを出力する」操作を最大 \( 100 \) 回まで繰り返した後、終了
(新たなグラフが操作前と一致するまで終了しない、とする元の設定から変更) - 「あるノードに対して、modularity が最大となるような隣接 community を見つける」操作を最大 \( 100 n \) 回 *) まで繰り返した後、終了
(すべてのノードにおいて、自身の community が modularity 最大のときに限り終了、とする元の設定から変更)- *) \( n \) はグラフのノード数
これらの仕様は予告なく変更される可能性があります。
KWIC
概要
KWIC (keyword in context) を表示します。以下のパラメータがあります。
| パラメータ | 初期値 | 説明 |
|---|---|---|
| 単語列 | 単語列を空白またはタブ区切りで指定します。 | |
| ウィンドウ幅 | 5 | 前後の単語数を指定します。 |
| 品詞フィルター | 内容語のみ表示 | 特定の品詞のみを表示、もしくは除外します。 |
品詞についての詳細はこちらを参照してください。
時系列ヒストグラム
概要
ドキュメントの日付情報を設定している場合、単語の出現頻度を時系列ヒストグラムで表示します。以下のパラメータがあります。
| パラメータ | 初期値 | 説明 |
|---|---|---|
| 単語列 | 単語列を空白またはタブ区切りで指定します。 | |
| 間隔 | 年別 | 時系列の時間間隔を、年別・月別・日別から選択できます。 |
日付の設定については時間・日付についてを参照してください。
対応分析
概要
項目の関係性(類似性や相違性)を視覚化する手法です。
登録されたプロジェクト内の単語頻度から算出された、単語列とメタデータのクロス集計結果を簡易的に表示します。偏りの大きい場合は原点から離れて、少ない場合は原点の傍にプロットされる傾向があります。また、近くにプロットされている項目同士は関連性が強く、離れてプロットされた項目は関連性が弱いと判定できます。
| パラメータ | 初期値 | 説明 |
|---|---|---|
| N | 1 | “単語 N-gram” の N を、1 以上 5 以下で指定します。 初期値の単語列の例)京都 |
| 単語数 | 20 | 表示する単語の数を 1 以上 1000 以下で指定します。 |
| 品詞フィルター | AND | N が 2 以上の場合、フィルターを AND または OR で適用します。 |
| 含める品詞 | 内容語のみ表示 | 特定の品詞のみを表示、もしくは除外します。 |
| クロス集計の対象 | 日付や著者など、プロジェクト登録時のファイルに含まれているメタデータの項目を選択できます。 | |
| フォントサイズ | 10 | 表示するフォントサイズを選択できます。 |
品詞についての詳細はこちらを参照してください。
LiTA を始める
ファイルをアップロードする
ログイン画面が表示されたら、利用規約をよく確認してからログインします。ログインには Google のアカウントが使えます。

ログインしたらホーム画面へ移動します。
ホーム画面では、[詳細] ボタンを押すことで利用規約、マニュアルとサンプルへのリンクが表示されます。
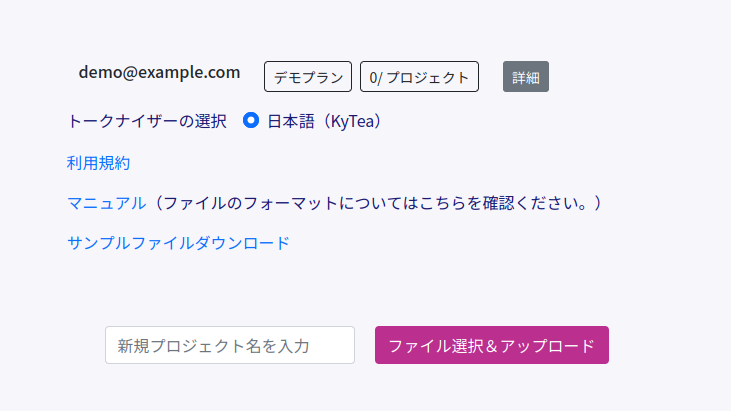 [トークナイザーの選択] では、新しく作成するプロジェクトで使用されるトークナイザーを選択できます。現在は日本語(KyTea)のみ選択可能です。
[トークナイザーの選択] では、新しく作成するプロジェクトで使用されるトークナイザーを選択できます。現在は日本語(KyTea)のみ選択可能です。
[サンプルファイルダウンロード] からは、青空文庫に収録された寺田寅彦の著書のうち、無作為に選んだ24件をダウンロードできます。 このファイルは、[ファイルを選択 & アップロード] からアップロードして試すこともできます。
[新規プロジェクト名を入力] では新しく作成するプロジェクトの名前を入力します。名前は最大で50文字までです。 省略した場合は「新規プロジェクト」という名前で作成されます。
[ファイルを選択 & アップロード] を押してファイルを選択すると、自動でアップロードされインデックス作成が始まります。 ファイルのフォーマットに関してはアップロードするファイルについてを確認してください。
※ プロジェクトが利用可能になるまで、
- アップロード
- インデックス作成
の二工程があります。アップロード中に中断(ページをリロード、ブラウザを閉じる等)した場合はプロジェクトを削除する必要があります。削除方法については下記に従ってください。インデックス作成中はページのリロード等をしても、プロジェクトを削除する必要はありません。
※ファイルサイズが大きい場合、これらの工程には時間がかかります。目安として、
- 10 MB → 数分
- 100 MB → 数十分
となります。
ファイルの選択後、次のような画面が表示されます。
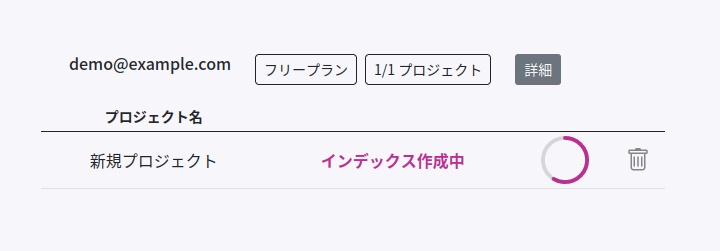
プロジェクト名の横には、アップロード中であればアップロードしたバイト数が、インデックス中であれば [インデックス作成中] の文字が表示されます。
アップロードおよびインデックス作成が完了したら、プロジェクトの詳細ページへ遷移します。
ファイルを追加でアップロードする
プロジェクトリストの ![]() をクリックすると、追加アップロードのページへ移動します。
をクリックすると、追加アップロードのページへ移動します。

そこでファイルを選択して、[ファイルをアップロード] でアップロードできます。 この場合でも上記と同じく、アップロードの中断はできません。途中でアップロードを止めてしまったときはプロジェクトの削除が必要になります。 インデックス作成中(アップロード完了後)は自由にページのリロード等が可能です。
エラーが発生したら
アップロードしたファイルのフォーマットが正しくない場合、エラーログのダウンロードリンクが表示されます。
 アップロードするファイルについてをよく読み、ファイルの中身を修正してから再アップロードします。再アップロードのためには、下記に従ってプロジェクトを削除し、上の手順を繰り返します。
アップロードするファイルについてをよく読み、ファイルの中身を修正してから再アップロードします。再アップロードのためには、下記に従ってプロジェクトを削除し、上の手順を繰り返します。
ファイルのフォーマットが正しいにも関わらずエラーが発生したときや、その他のエラーに遭遇したときは、しばらく時間を空けてからもう一度お試しください。 それでも改善しない場合は Linfer まで連絡をお願いします。
プロジェクトを削除する
プロジェクトリストのゴミ箱アイコン ![]() をクリックすると、プロジェクトを削除するための確認が表示されます。
をクリックすると、プロジェクトを削除するための確認が表示されます。
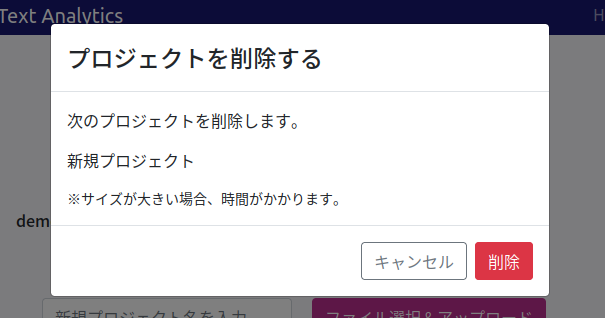
[削除] をクリックするとプロジェクトが削除されます。
※削除されたプロジェクトは復元できません。慎重に操作してください。
アップロードするファイルについて
アップロードできるファイルは、次のうちいずれかです。
- CSV ファイル(
.csv) - JSON ファイル(
.json) - テクストファイル(
.txt、.text)
複数のファイルをアップロードすることも可能ですが、以下の注意点を確認してください。
文字コード
対応している文字コードは UTF-8、SHIFT-JIS、UTF-16、EUC-JP、ISO-2022-JP です。 どれでも機能に差はありませんが、UTF-8 が最も推奨されます。
なお、Excel でデータを作成される場合は、「CSV(コンマ区切り)」(Shift JIS) を選択してください。 「CSV UTF-8(コンマ区切り)」(UTF-8 BOM 付き) の形式は現在アップロードできません。
複数ファイルをアップロードする際の注意点
複数のファイルをアップロード場合、すべてのファイルのスキーマを合わせる必要があります。 スキーマとは、「どのメタデータ(タイトル、日付、著者など)を持っているか」という情報のことで、プロジェクトごとに一つのスキーマがあります。
LiTA では一つめのファイルを読み込むときに自動でスキーマを決定しますが、そのスキーマと整合しないファイルをアップロードすることはできません。 すべてテクストファイルであれば問題ありませんが、CSV ファイルとテクストファイルが混ざっていたり、CSV ファイルが複数ある場合には注意してください。 どのようにスキーマが決定されるかについては、ファイル形式の詳細以下の各項を参照してください。
ファイル形式の詳細
スキーマは id、body とその他のメタデータから構成されます。
言い換えれば、各ドキュメントは必ず ID と本文を一つ持ち、それ以外のメタデータは任意です。ただし、メタデータはすべてのドキュメントで共通でなければなりません。
ID はすべてのドキュメントで一意となるよう必要があります。複数のファイルに同じ ID が含まれないよう注意してください。
たとえば
{
id: 1,
body: テスト1,
date: 2022-01-01,
},
{
id: 2,
body: テスト2,
date: 2022-01-02,
}
であればアップロードできますが(メタデータのスキーマが等しい)、
{
id: 1,
body: テスト1,
date: 2022-01-01,
},
{
id: 2,
body: テスト2,
}
はアップロードできません(ID 1 のメタデータには date があるが、ID 2 には無い)。
以下の例は ID の重複があり、正しく動作しない恐れがあります。
{
id: 1,
body: テスト1,
date: 2022-01-01,
},
{
id: 1,
body: テスト2,
date: 2022-01-02,
}
CSV ファイル
CSV ファイルの場合、ファイルの一行目にヘッダ行を付けてください。Excel などでは自動で付けられることもあります。 たとえば
id,body,date,author
1,テスト1,2022-01-01,John Doe
2,テスト2,2022-01-02,John Doe
3,テスト3,2022-01-02,Jane Doe
という CSV ファイルであれば、id、body、date、author という4つのメタデータを持ちます。
メタデータの順番は任意ですが、必ず id と body を入れてください。
また実装の都合上、title = id として扱われます。
したがって、メタデータに title を含めたい場合は別の名前のフィールドにしてください。
この仕様は今後変わる可能性があります。
JSON ファイル
JSON ファイルの中身は、ドキュメントの配列を表す JSON になります。
ダブルクォーテーション(")を忘れないようにしてください。
メタデータについては、CSV ファイルと同様の制約を受けます。詳しくは CSV ファイルの項を参照してください。
例:
[
{
"id": "1",
"body": "テスト1",
"date": "2022-01-01"
},
{
"id": "1",
"body": "テスト2",
"date": "2022-01-02"
}
]
テクストファイル
テクストファイルの場合、ファイル名がそのまま id となり、ファイルの中身が body となります。
それ以外のメタデータは存在しません。
時間・日付について
トピックモデルの時系列表示や時系列ヒストグラムなど、LiTA の一部の機能には時間情報を利用するものがあります。そのような機能を使用する場合は、date というメタデータが必須です。
なお、これらの機能を使用しない場合は、date の指定は不要です。
将来的に date 以外のメタデータも指定できるようになりますが、現時点で実装時期は未定です。
date のフォーマットに関する細かい仕様は、各機能によって異なりますが、基本的には西暦で yyyy-mm-dd となっています。
例:1990-01-10。
機能ごとのフォーマット
トピックモデル
日付のフォーマットは以下のいずれかを選択できます。
- 年月日:
1990-01-10 - 年月日 + 時刻:
1990-01-10 09:00:00 - RFC 3339 によるタイムスタンプ形式:
1990-01-10T09:00:00Z
時系列ヒストグラム
日付のフォーマットは yyyy-mm-dd となります。ただし、以下の点に注意してください。
-
年のみ、年月のみの指定はできません。必ず年月日まで指定してください。 月日が不要の場合でも、
01月01日など適当な日付を付け足す必要があります。 -
いわゆる proleptic Gregorian calendarを採用しています。つまり、
1500-01-01はユリウス暦の 1500 年 1 月 1 日ではなく、グレゴリオ暦の 1500 年 1 月 1 日と解釈されます。 -
紀元前は 0 以下の年で表されます。
例)紀元前 1 年 1 月 1 日 →
0000-01-01紀元前 100 年 1 月 1 日 →
-0099-01-01とくに、閏年の扱いに注意が必要です。
例)-5 年 (6 BC) は閏年ではなく、-4 年 (5 BC) が閏年に該当します。
時系列ヒストグラムでは、日付より細かい時間単位(時・分など)を扱う機能はありません。
品詞について
品詞の種類は以下の通りです。
内容語:
- 名詞
- 動詞
- 接尾辞
- 形容詞
- 代名詞
- 副詞
- 形状詞
- 連体詞
- 接頭辞
- 接続詞
- 感動詞
機能語:
- 助詞
- 補助記号
- 語尾
- 助動詞
- URL
- 記号
- 空白
- 言いよどみ
- 英単語
用語解説
ドキュメント
プロジェクトに含まれる各テキスト群を「ドキュメント」として扱います。1 ドキュメントは、アップロード時の 1 ファイルまたは 1 ID に相当します。
プロジェクト
一度にアップロードしたテキスト(群)は「一つのプロジェクト」として登録され、プロジェクト単位で分析いただけます。(複数プロジェクトを同時には分析いただけません。)
「My project」に表示されるタイトルは、プロジェクト画面(分析ページ)のタイトル表示部をクリックし、編集いただけます。
ペイン
プロジェクト画面において、一つの機能(分析ツール)を表示する各ボックスがペインです。ペインヘッダーには、各機能におけるパラメータ設定のボタン等が表示されています。
ペインレイアウト
プロジェクト画面において、ペインの配置を 4 パターンから選択いただけます。プロジェクトタイトルの左隣に表示されているウィンドウアイコンをクリックし、希望するレイアウトを選択してください。スマートフォンでご覧いただく場合は 2 ペイン表示を推奨いたします。
Bookshelf
青空文庫や Wikipedia 記事など、規約に基き公開可能であるテキストについて、事前にプロジェクト登録を行い、公開しています。「Bookshelf」に登録済のプロジェクトは、全ユーザーに表示されます。
My project
ユーザーが登録したテキスト(群)は、「My project」に表示されます。登録ユーザー本人にのみ表示されます。
Share project
ユーザーが登録したテキストを別のユーザーに共有することが可能です。(メールアドレスによる指定)
共有されたユーザーには「Share project」として表示されます。