Procedural Text Understanding/Generation
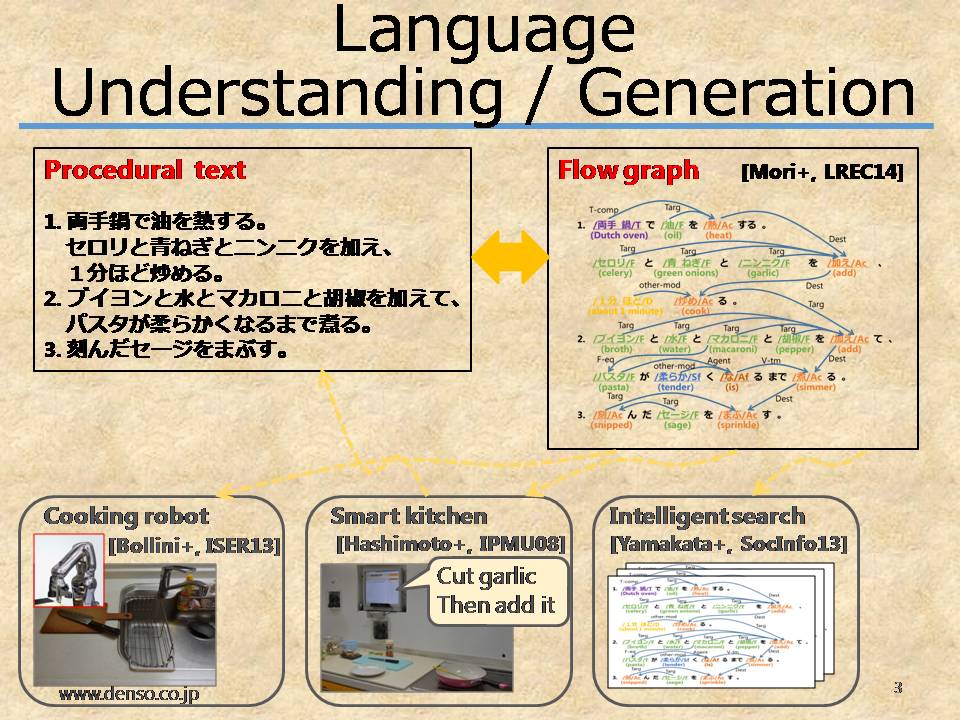
We study on the language understanding, the ultimate goal of natural language procesing (NLP). Understanding is a difficult problem without clear definition. But if we limit the target to procedural texts describing what to do how, we can represent the meaning by a graph. We are studying an automatic graph representation from texts and an automatic description from video.
Now we are solving the problem by decomposing them as follows.
- Procedural Text to Flow Graph (T2FG)
- Word identification
- Important term recognition
- Flow graph construction
- Flow Graph to Procedural Text (FG2T)
- Video to Procedural Text (CV2T)
- Recognition of objects and actions (computer vision group)
- Sentence generation
We have built data sets for the research.
Selected Publications
- A Framework for Procedural Text Understanding
- Hirokuni Maeta, Tetsuro Sasada, Shinsuke Mori.
- IWPT, 2015.
- Flow Graph Corpus from Recipe Texts
- Shinsuke Mori, Hirokuni Maeta, Yoko Yamakata, Tetsuro Sasada
- LREC, pp.2370-2377, 2014.
Game Commentary Generation

Our aim is practical language generation. So our method learns automatically what-to-say based on symbol grounding technique. In addition, it learns how-to-say from a huge number of examples based on a machine learning technique. By combining what-to-say and how-to-say, it generates sentences in a natural language.
Concretely we are working on commentary generation of Shogi, Japanese chess. Now computers play as good as top professional players, so it is interesting to verbalize computer's thought.
Current framework is as follows.
- Preparation
- Text analysis
- Deep learning to connect states and text fragments (symbol grounding)
- Language model construction (word 3-gram model, recurrent neural network)
- Commentary generation for a new state
- Decide what-to-say from the piece distribution
- Sentence generation referring to what-to-say and the language model
With Tsuruoka lab. in the University of Tokyo.
Selected Publications
- Learning a Game Commentary Generator with Grounded Move Expressions
- Hirotaka Kameko, Shinsuke Mori, Yoshimasa Tsuruoka,
- IEEE CIG, 2015.
Fundamental Text Analysis
We are studying and developing practical text analysis tools. Our aim is that our tools are accurate and robust to texts in various domains. Starting with well-known KyTea, we have made and will make public the following tools.- KyTea: Word segmentation, Pronunciation estimation, and Part-of-speech tagging tool for Japanese and Chinese
- PWNER: Important term recognition
- EDA: Dependency parsing
- PASA: Predicate-arguent structure analysis
Selected Publications
- Pointwise Prediction for Robust, Adaptable Japanese Morphological Analysis
- Graham Neubig, Yosuke Nakata, Shinsuke Mori
- ACL-HLT, 2011.
- Named Entity Recognizer Trainable from Partially Annotated Data
- Tetsuro Sasada, Shinsuke Mori, Tatsuya Kawahara and Yoko Yamakata,
- PACLING, 2015.
- A Pointwise Approach to Training Dependency Parsers from Partially Annotated Corpora
- Daniel Flannery, Yusuke Miyao, Graham Neubig, Shinsuke Mori
- Natural Language Processing, Vol.19, No.3, pp.167-191, September, 2012.
- Predicate Argument Structure Analysis using Partially Annotated Corpora
- Koichiro Yoshino, Shinsuke Mori, Tatsuya Kawahara
- IJCNLP, pp.957-961, 2013.
Language Resource Development
For tool development and evaluation, we are building various language resources. In addition, we make them publicly available to contribute to the society.Kyewords: Recipe, Procedural text, Game commentary, Data commentary, natural language processing (NLP), natural language generatoin (NLG), word segmentation, part-of-speech tagging, pronunciation estimation, parsing
Last Change: 2015/07/24 by Shinsuke MORI
