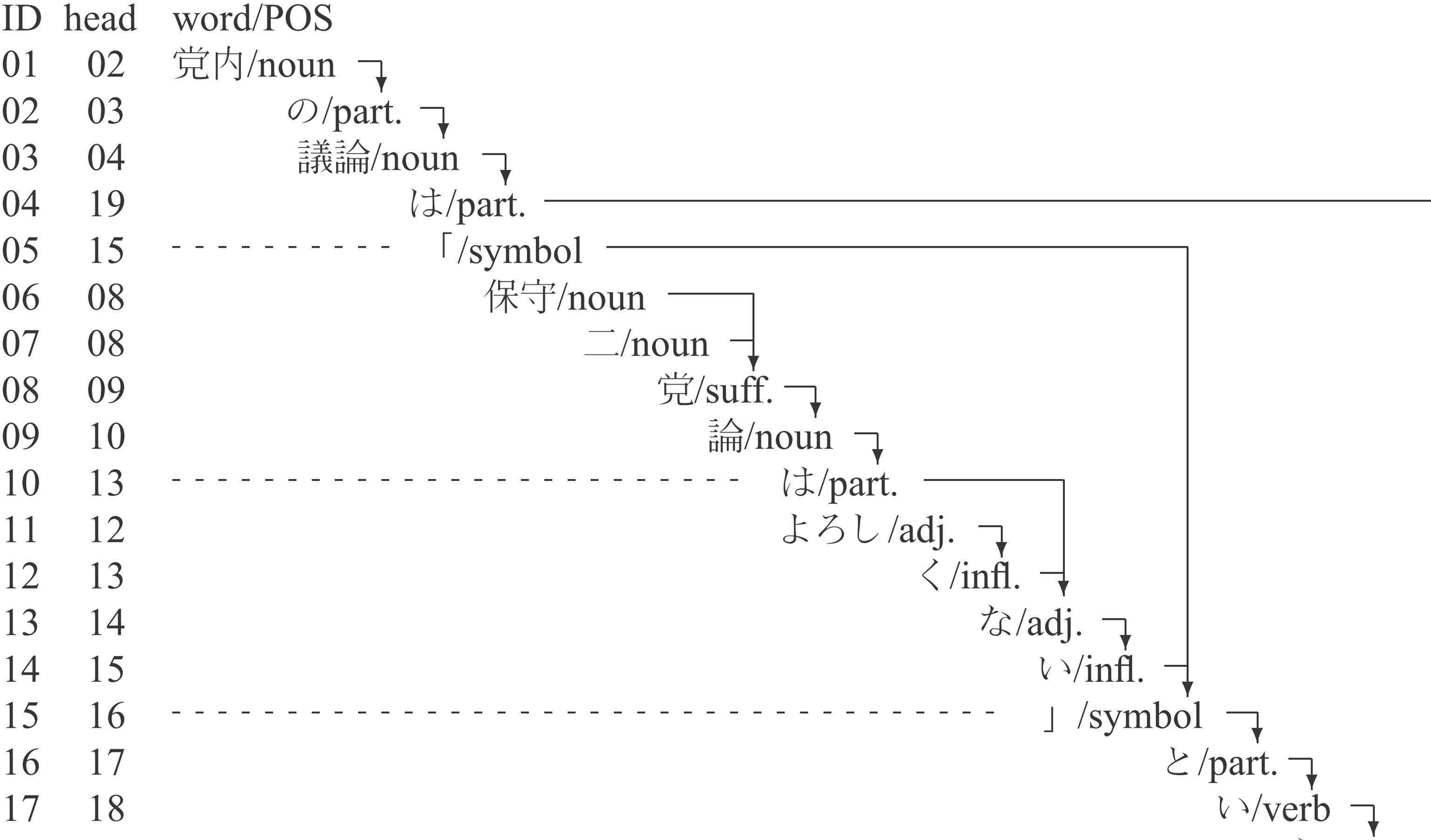
 We are constructing a publicly available dependency corpus in Japanese.
The unit is, as in many languages, words.
We are constructing a publicly available dependency corpus in Japanese.
The unit is, as in many languages, words.
Now we have about 35,000 annotated sentences taken from various sources such as blogs. The annotated date are as follows.
We are also distributing a parser EDA trained on the data.
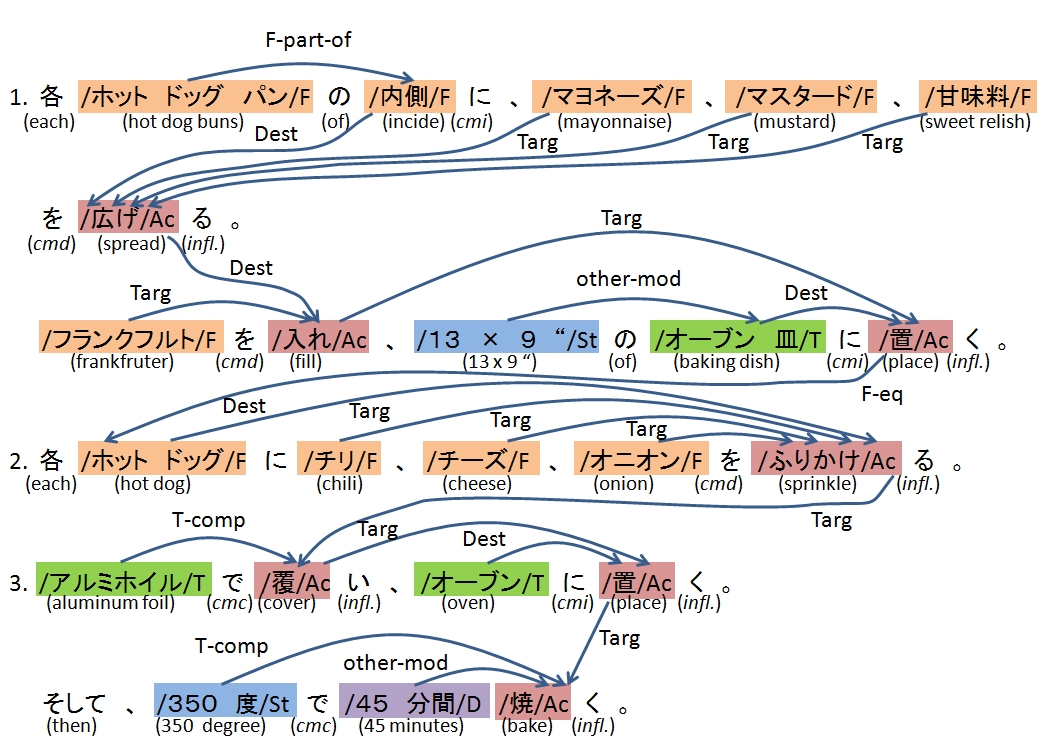 We have proposed to represent the meaning of procedural texts as flow graphs (directed
acyclic graph).
As the representative of procedural texts we have adopted recipes, of which there are
many sites or books.
We defined eight types of important terms and represent their relationships by a
directed acyclic graph (DAG).
We have annotated recipes with the following information and made them public.
We have proposed to represent the meaning of procedural texts as flow graphs (directed
acyclic graph).
As the representative of procedural texts we have adopted recipes, of which there are
many sites or books.
We defined eight types of important terms and represent their relationships by a
directed acyclic graph (DAG).
We have annotated recipes with the following information and made them public.
The framework can cover general procedural texts just by replacing "food" with "parts." Please take a look at the details if you are interested in it.
We are also distributing a named entity recognizer PWNER trained on the data. And we are developping a flow graph constructor.
We are also distributing a word segmenter, POS tagger, and pronuciation estimater KyTea including this data.
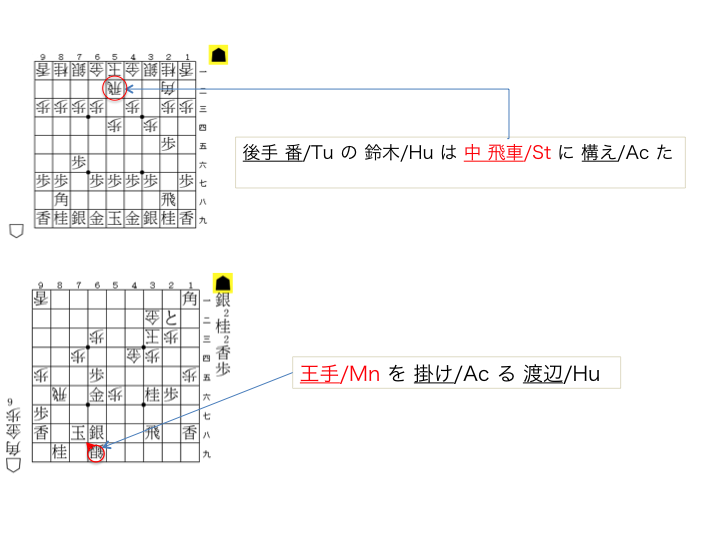 This is a corpus consisting of pairs of a game state and commentary sentences on it.
The game is shogi (Japanese chess).
Words in each sentences are identified and annotated game term tags.
We defined 21 game term types.
This is a corpus consisting of pairs of a game state and commentary sentences on it.
The game is shogi (Japanese chess).
Words in each sentences are identified and annotated game term tags.
We defined 21 game term types.
A word segmenter and part-of-speech tagger, KyTea, trained from this corpus is available. A term recognizer, PWNER, is also available.
 This corpus allows us to develop a tool for connecting expressoins in a text and world knowledge.
The annotated texts contains sentences in BCCWJ as well as those in Twitter.
This corpus is useful for wikification of various texts.
This corpus allows us to develop a tool for connecting expressoins in a text and world knowledge.
The annotated texts contains sentences in BCCWJ as well as those in Twitter.
This corpus is useful for wikification of various texts.
We are devising a wikification tool based on it.
Collaboration with prof. Yugo Murawaki of Graduate School of Informatics, Kyoto University
 This is a multi-modal dataset of activity observation in a kitchen, one of operations according to procedural texts.
The dataset includes
This is a multi-modal dataset of activity observation in a kitchen, one of operations according to procedural texts.
The dataset includes
We constructed a Japanese corpus which consists of "Featured Article" and "Good Article" in Japanese Wikipedia.
We performed data cleansing as preprocessing.
This project was conducted by refering to The wikitext long term dependency language modeling dataset.
This is a dataset annotated with coordinates of location expressions in Wikipedia articles. The dataset is automatically generated by using the coordinates of articles and the hyperlink structure of Wikipedia.
This is a dataset for vision and language tasks in biochemistry. The dataset is constructed by annotating ego-centric videos of biochemistry experiments with natural language descriptions.