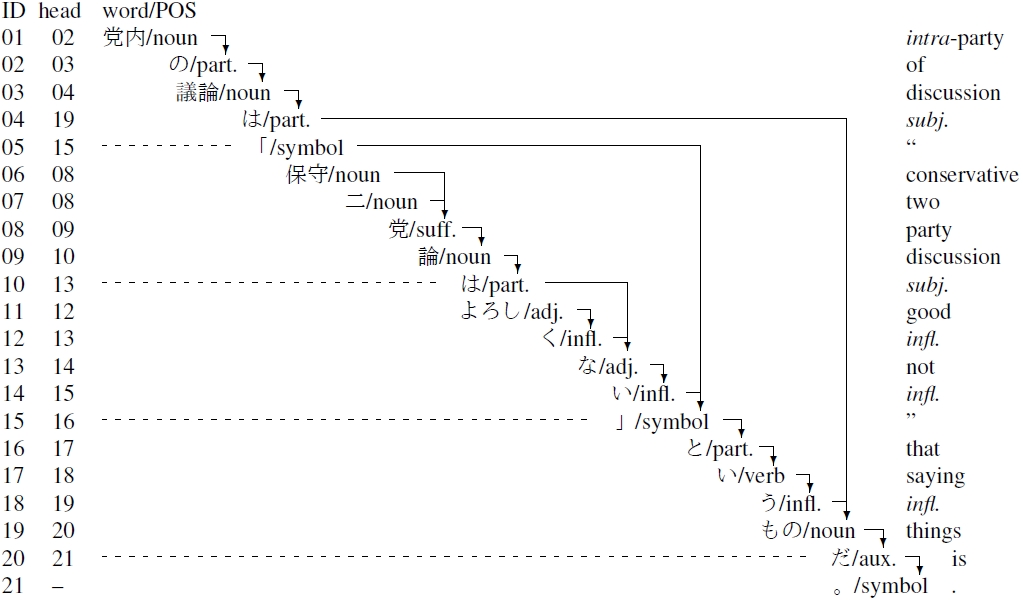
 We construct and publish the Japanese Dependency Corpus (JDC).
We construct and publish the Japanese Dependency Corpus (JDC).
We take sentences from various domains to allow corpus users to conduct domain adaptation experiments.
The unit of JDC is word like other languages contrary to existing Japanese corpora whose unit is phrase called bunsetsu. For the definition of word, we follow "short-unit words" of the Balanced Corpus of Contemporary Written Japanese (BCCWJ), which is a mature standard created by linguists of Japanese language. The only difference is that we separate the endings of inflectional words (adjectives, verbs, and auxiliary verbs) from their stems.
The target of our research is written Japanese, which is a head-final language.
We assume that in Japanese dependencies go from left to
right and that every word except for the last one in a sentence depends on exactly one other word.
We do not make the assumption that dependencies do not cross,
because even in written Japanese such dependencies may occur in informal contexts.
| Category | #Sent. | #Words | #Char. | ||
| BCCWJ | ClassA + 2012 (train) |
OC | 1,614 | 33,078 | 46,435 |
| OW | 1,552 | 62,735 | 90,610 | ||
| OY | 1,858 | 31,563 | 46,481 | ||
| PB | 2,254 | 53,037 | 73,194 | ||
| PM | 2,514 | 42,800 | 65,245 | ||
| PN | 2,590 | 57,319 | 83,985 | ||
| subtotal | 12,382 | 280,532 | 405,950 | ||
| ClassA-1 (test) |
OC | 500 | 9,846 | 13,752 | |
| OW | 504 | 23,952 | 34,203 | ||
| OY | 509 | 9,239 | 13,340 | ||
| PB | 511 | 11,792 | 16,512 | ||
| PM | 495 | 7,415 | 10,396 | ||
| PN | 505 | 12,621 | 18,456 | ||
| subtotal | 3,024 | 74,865 | 106,661 | ||
| subtotal | 15,406 | 355,397 | 512,611 | ||
| EHJ | train | 11,700 | 147,964 | 198,196 | |
| test | 1,300 | 16,433 | 21,950 | ||
| subtotal | 13,000 | 164,397 | 220,146 | ||
| NKN | train | 9,023 | 263,425 | 398,567 | |
| test | 1,002 | 29,037 | 43,694 | ||
| subtotal | 10,025 | 292,462 | 442,262 | ||
| RCP | train | 662 | 12,008 | 18,174 | |
| test | 62 | 1,139 | 1,786 | ||
| subtotal | 724 | 13,147 | 19,961 | ||
| JNL | train | 322 | 12,263 | 20,332 | |
| test | 32 | 1,116 | 1,868 | ||
| subtotal | 354 | 13,379 | 22,200 | ||
| NPT | train | 1,750 | 71,208 | 111,394 | |
| test | 250 | 10,497 | 16,409 | ||
| subtotal | 2,000 | 81,705 | 127,803 | ||
| total | 41,509 | 920,487 | 1,345,041 | ||
Each word, except for the root word, is annotated with its head (dependency destination). Thus the number of dependencies in a corpus is equal to the number of words minus the number of sentences.
The JDC are composed of the following sources:
The followings are subcategories of BCCWJ Core data:
Simple sentence
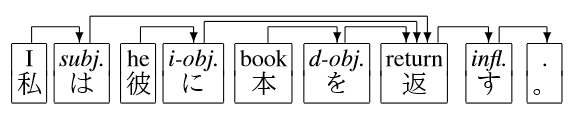
Basically Japanese is an SOV language. That is to say, the word order in a simple sentence is subject, object, and verb. Almost all noun phrases have a case marker called postposition to clarify its role to the verb. The only limitation is to put the main verb phrase at the end. That is to say, subject (subj.), direct object (d-obj.), indirect object (i-obj.), and other verb modifier such as adverbial phrases are ordered freely.
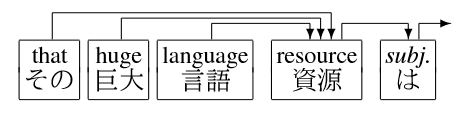 Compound word
Compound word
We annotate a compound word with the structure representing its meaning. Modifiers of a compound word depend on its head (in many cases with very few exceptions which modifies a part of a compound word) and there is only one dependency arc going out from the head.
Copula
Some sentences have a copular verb. Most copula sentences fall into the following type:
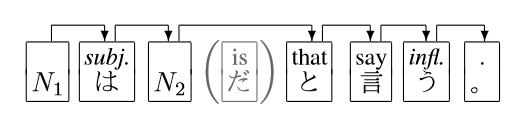 N 1 は/subj. N 2 だ/is
N 1 は/subj. N 2 だ/is
We decided that the case marker "は/subj." depends on N 2, not on the auxiliary verb "だ/is." The reason is that an auxiliary verb can be omitted especially in a that-clause or sentence coordination. The head of the case marker is always N 2 independent from the existence of an auxiliary verb.
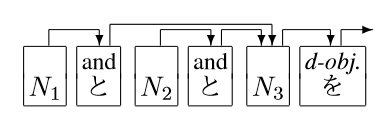 Coordination
Coordination
In a coordination structure two or more phrases are concatenated by using a coordination marker. In Japanese the most frequent marker is "と/and." This marker is similar to "and" in English but we put one at each point between elements.
| Test\Train | BCCWJ | All full | +partial |
| ClassA-1-OC | 93.09 | 92.99 | |
| ClassA-1-OW | 88.72 | 88.91 | |
| ClassA-1-OY | 92.30 | 92.46 | |
| ClassA-1-PB | 90.68 | 90.94 | |
| ClassA-1-PM | 93.14 | 92.59 | |
| ClassA-1-PN | 91.17 | 91.33 | |
| EHJ-test | 96.43 | 96.97 | |
| NKN-test | 91.43 | 92.77 | |
| RCP-test | 86.63 | 92.85 | |
| JNL-test | 84.23 | 90.59 | |
| NPT-test | 87.41 | 92.64 | |
Training corpus:
- A Japanese Word Dependency Corpus
- Shinsuke Mori, Hideki Ogura, Tetsuro Sasada
- LREC, pp.753-758, 2014.
- A Pointwise Approach to Training Dependency Parsers from Partially Annotated Corpora
- Daniel Flannery, Yusuke Miyao, Graham Neubig, Shinsuke Mori
- Natural Language Processing, Vol.19, No.3, pp.167-191, September, 2012.
- Training Dependency Parsers from Partially Annotated Corpora
- Daniel Flannery, Yusuke Miyao, Graham Neubig, Shinsuke Mori
- IJCNLP, pp.776-784, 11/10, 2011.