手続き文書の理解・生成
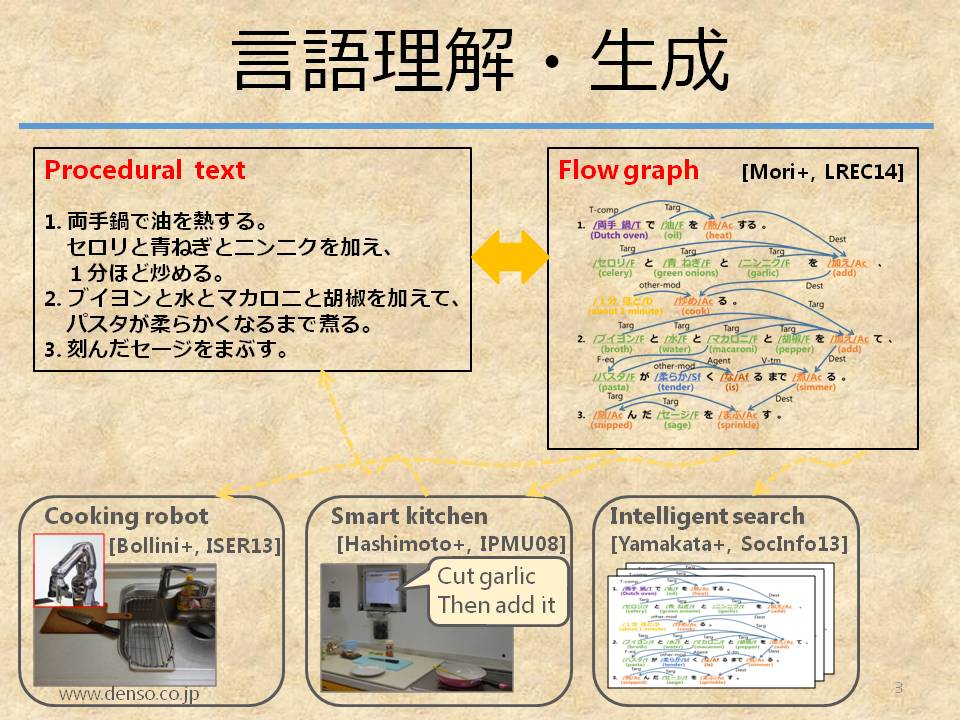
自然言語処理の究極の目標である「理解」の研究をしています。 「理解」は定義すらはっきりしない困難な課題です。 しかし、何をどうするかを書いている手続き文書に限定すれば意味をグラフで表現できます。 文書からのグラフ生成やビデオからの文書生成について研究しています。
現在は以下のように問題を分解して解いています。
- 手続き文書からフローグラフへ (T2FG)
- 単語分割
- 重要語認識
- フローグラフ生成
- フローグラフから手続き文書へ (FG2T)
- 実施ビデオから文書へ (CV2T)
- 物体と動作の認識 (映像処理グループ)
- 文生成
研究のためのデータも作成しました。 主に、美濃研 (飯山将晃准教授, 橋本敦助教)、および 東京大学の相澤研 (山肩洋子博士)と共同で研究しています。
Selected Publications
- A Framework for Procedural Text Understanding
- Hirokuni Maeta, Tetsuro Sasada, Shinsuke Mori.
- IWPT, 2015.
- Flow Graph Corpus from Recipe Texts
- Shinsuke Mori, Hirokuni Maeta, Yoko Yamakata, Tetsuro Sasada
- LREC, pp.2370-2377, 2014.
分析や予測の結果を話すコンピューター

コンピュータはデータ分析や未来予測に活躍しています。 今は、分析や予測の結果の数値を専門家が見て、他の人に解説しています。 コンピュータ自身にそれを語ってもらうことを目指しています。
そのために、「言う事」をシンボルグラウンディングによって自動的に決定します。 また、大量の例文から機械学習を用いて「言い方」を学習しておきます。 「言う事」と「言い方」を合わせて自然言語の文を生成します。
最初の対象として、将棋の自動解説に取り組んでいます。 コンピュータ将棋は、プロ棋士に比肩するので、その思考を言語化するのは面白い課題です。
一般的なデータ分析や予測を想定して、以下のような手順で解説生成をしています。
- 準備
- 例文の自然言語解析
- 盤面と表現の自動対応 (シンボルグラウンディング)
- 言語モデルの学習 (単語3-gramモデル, リカレント・ニューラル・ネットワーク)
- 新しい盤面に対する解説生成
- 盤面からの「言う事」の推定
- 「言う事」と言語モデルを参照しつつ文生成
これで自動的に解説文が出力できます。 プロ級の知識が必要な戦型予想などを見事に行えるようになりました。 しかし、全体ではまだまだプロには及ばないので、様々な研究の余地があります。 例えば、「言う事」と「言い方」の両方を深層学習で行うことなどを研究しています。
東京大学の鶴岡研と共同で研究しています。 詳細は鶴岡研亀甲君のページをご覧ください。
Selected Publications
- Annotating Modality Expressions and Event Factuality for a Japanese Chess Commentary Corpus
- Suguru Matsuyoshi, Hirotaka Kameko, Yugo Murawaki, Shinsuke Mori
- LREC, 2018.
- Game State Retrieval with Keyword Queries
- Atsushi Ushiku, Shinsuke Mori, Hirotaka Kameko, Yoshimasa Tsuruoka,
- ACM SIG IR, 2017.
- Learning a Game Commentary Generator with Grounded Move Expressions
- Hirotaka Kameko, Shinsuke Mori, Yoshimasa Tsuruoka,
- IEEE CIG, 2015.
学知のためのテキスト解析
学問的な知に関するテキストやメディアの解析に取り組んでいます。
当面の課題として、以下の問題の解決方法について研究しています。
- テキスト検索 (Text2Feature)
- Wikification
- Spatio-temporal NLP
東南アジア研究研究所 と共同で研究しています。
Selected Publications
- Wikification for Scriptio Continua
- Yugo Murawaki, Shinsuke Mori
- LREC, pp.1346-1351, 2016.
- errata
基礎的なテキスト解析

使える基礎的なテキスト解析を研究・開発しています。 様々な分野のテキストを高精度で頑健に解析できるようにすることが課題です。
よく知られた KyTea をはじめとして、以下のツールを公開しています。
また、以下のデータを公開しています。
Selected Publications
- Pointwise Prediction for Robust, Adaptable Japanese Morphological Analysis
- Graham Neubig, Yosuke Nakata, Shinsuke Mori,
- ACL-HLT, 2011.
- Named Entity Recognizer Trainable from Partially Annotated Data
- Tetsuro Sasada, Shinsuke Mori, Tatsuya Kawahara and Yoko Yamakata,
- PACLING, 2015.
- A Pointwise Approach to Training Dependency Parsers from Partially Annotated Corpora
- Daniel Flannery, Yusuke Miyao, Graham Neubig, Shinsuke Mori,
- Natural Language Processing, Vol.19, No.3, pp.167-191, September, 2012.
- Predicate Argument Structure Analysis using Partially Annotated Corpora
- Koichiro Yoshino, Shinsuke Mori, Tatsuya Kawahara,
- IJCNLP, pp.957-961, 2013.
言語資源の構築・公開
ツールの作成や評価のために様々な言語資源を構築しています。 また、社会への貢献のためにもできるだけ公開しています。