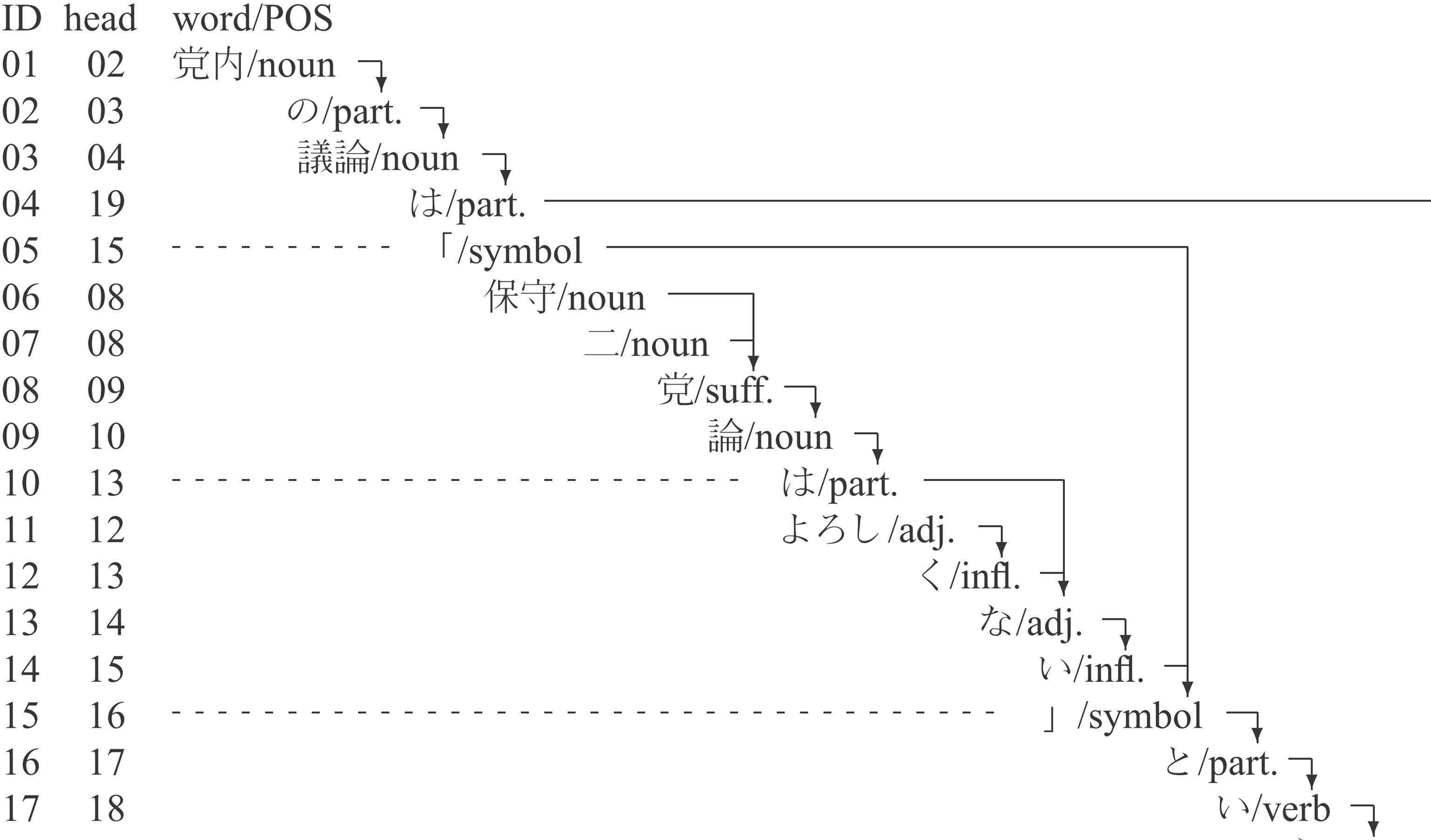
 日本語の係り受けコーパスを作成・公開しています。
単位は、多くの言語で標準となっている単語としています。
日本語の係り受けコーパスを作成・公開しています。
単位は、多くの言語で標準となっている単語としています。
現在、ブログなどを含む様々な文章に対して約35,000文のアノテーションがあります。 付与されいてる情報は以下の通りです。
このデータで学習した係り受け解析機 EDA も公開しています。
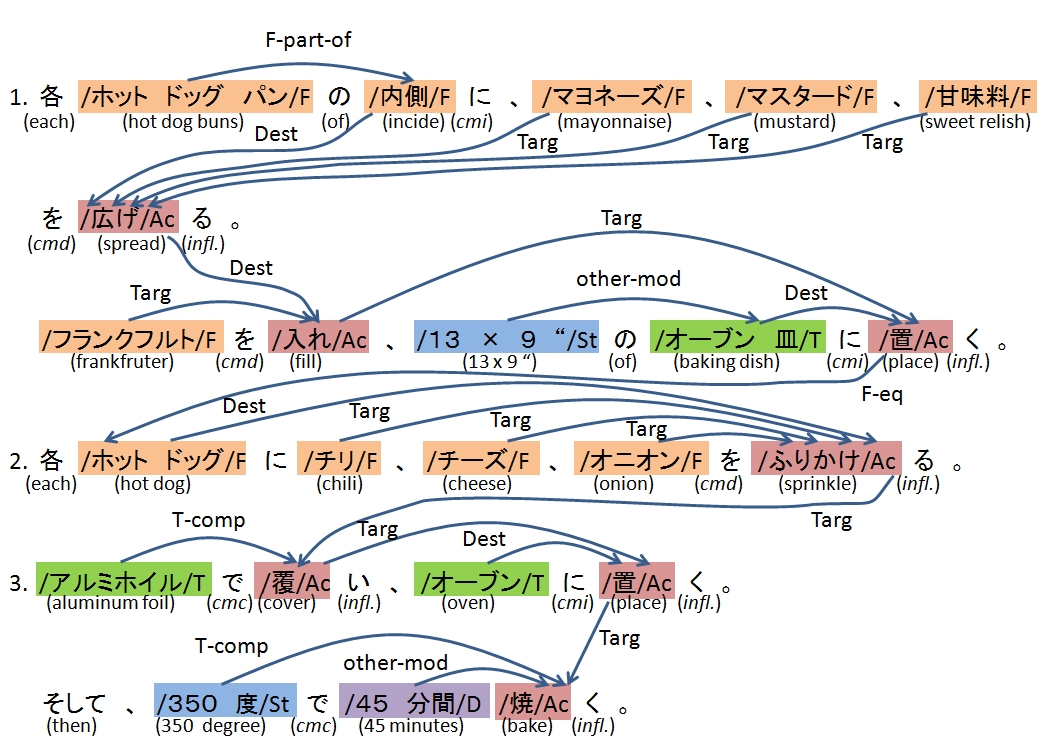 手順書の意味をフローグラフ(非巡回有向グラフ)で表現することを提案しました。
手順書の代表としてサイトや書籍が最も豊富なレシピを採用しました。
8種類の重要語を定義し、その関係を非巡回有向グラフ(DAG)で表現します。
実際にレシピに以下のアノテーションを行い、公開しています。
手順書の意味をフローグラフ(非巡回有向グラフ)で表現することを提案しました。
手順書の代表としてサイトや書籍が最も豊富なレシピを採用しました。
8種類の重要語を定義し、その関係を非巡回有向グラフ(DAG)で表現します。
実際にレシピに以下のアノテーションを行い、公開しています。
なお、食材をパーツに置き換えることで、一般の手順書に対応できます。 ご興味のある方は詳細をご覧ください。
このデータで学習した固有表現認識器 PWNER も公開しています。 また、フローグラフ生成ツールも構築中です。
このデータを反映した形態素解析器(単語分割、品詞推定、読み推定) KyTea を配布しています。
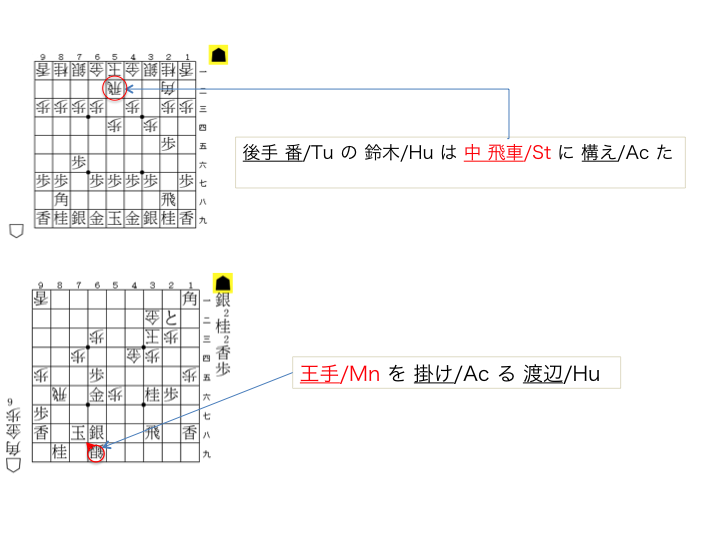 将棋の盤面とそれに対応する解説からなるコーパスです。
解説の文は、単語分割に分割され、将棋用語タグが付与されています。
将棋用語は、独自に定義した21種類です。
将棋の盤面とそれに対応する解説からなるコーパスです。
解説の文は、単語分割に分割され、将棋用語タグが付与されています。
将棋用語は、独自に定義した21種類です。
さらに、モダリティ表現のアノテーションも行った。 モダリティ表現は、否定や推量、仮定などの情報発信者の態度の表出であり、 実世界(盤面)を参照しつつモダリティ表現を解析する研究の題材となる。
このデータを反映した形態素解析器(単語分割、品詞推定、読み推定) KyTea と PWNER と 自動用語認識器を配布しています。
モダリティー解析モデルは現在構築中です。
 テキストを外部知識と関連づける Wikification のためのコーパスです。
BCCWJ に加えて Twitter のテキストに対してもアノテーションしています。
より多様なテキストに対する Wikification の研究に役立つと考えられます。
テキストを外部知識と関連づける Wikification のためのコーパスです。
BCCWJ に加えて Twitter のテキストに対してもアノテーションしています。
より多様なテキストに対する Wikification の研究に役立つと考えられます。
これを用いた Wikification のツールも開発中です。
京都大学大学院情報学研究科の村脇有吾先生との共同研究です。
 手順書に従って行われる作業の一つである調理作業の様子を多様な観測装置を備えたキッチンにより記録したマルチモーダルデータセットです.
映像を中心として,サーモカメラや荷重センサ,電力センサ(IHコンロ),上下水道の流量センサなどのデータがあります.
対象となるレシピは手順書のフローグラフに含まれる20種類となっています(対応表).
手順書に従って行われる作業の一つである調理作業の様子を多様な観測装置を備えたキッチンにより記録したマルチモーダルデータセットです.
映像を中心として,サーモカメラや荷重センサ,電力センサ(IHコンロ),上下水道の流量センサなどのデータがあります.
対象となるレシピは手順書のフローグラフに含まれる20種類となっています(対応表).
「質の良い」日本語テキストコーパスとして、日本語版Wikipediaにおいて「秀逸な記事」および「良質な記事」と認定されている記事を収集したコーパスです。
前処理としてのデータクレンジングも事前に施しています。
本プロジェクトは The wikitext long term dependency language modeling dataset を参考に実施されました。